Part 8 : Following along MIT intro to deep learning
Abhijit Ramesh / April 04, 2021
11 min read • ––– views
Bias and Fairness
Introduction
AI applications that uses Neural Networks under the hood is widely adapted currently in the real world and advancement in this field is increasing day by day. One of the major problem that AI is facing is that of algorithmic bias. As we have seen already we understand that our algorithms are only as good as our data and if our data is biased our algorithm is also biased. This effects in a lot of places everything from facial recognition to making decision in medical processes. The need to compact these biases are hence necessary.
What is bias ?
Let us look at the image of a watermelon and think of some description for the same.

It is more likely that we describe these as simply "watermelon" instead of something like "red watermelon" but what if we are shown this image instead ?

Then it is more likely that we go for answers such as yellow watermelon. Why does this happen even though both are simply watermelon ?
We don't think about watermelon with Red flesh as red watermelon because this is prototypical to us. As human beings it is our nature to reduce complex sensory inputs into simple groups so that they are more easy to understand and communicate.
But to a person who is living in a place where the yellow watermelons are more common, they might be inclined to classify the yellow once as simply watermelons. The rest of us will consider these once as atypical.
These kids of biases and stereotypes also arise in data labelling which will make its way into the data and hence the model itself weather it is done by humans or artifically.
Bias in Machine Learning

A study was conducted on facial recognition systems that were in production by top companies with images of faces from around the world and it showed that the algorithm was miss classifying images of darker females compared to the other classes. Another study also on facial recognition shows that many algorithms have more error in classifying faces of colours as in comparison to white faces.
Similarly when the image of a bride was passed into the model which is a typical bride from North America or Europe the following was the prediction.

But when we pass in an image of a bride from East Asia the predictions were,

This is not saying that the image is of a bride even though the same is seen above.
The same was the case when images of spices from US was compared to spices from philipeans which also showed similar result.
The accuracy of the images were correlated with the income of the homes from which the test image was generated.
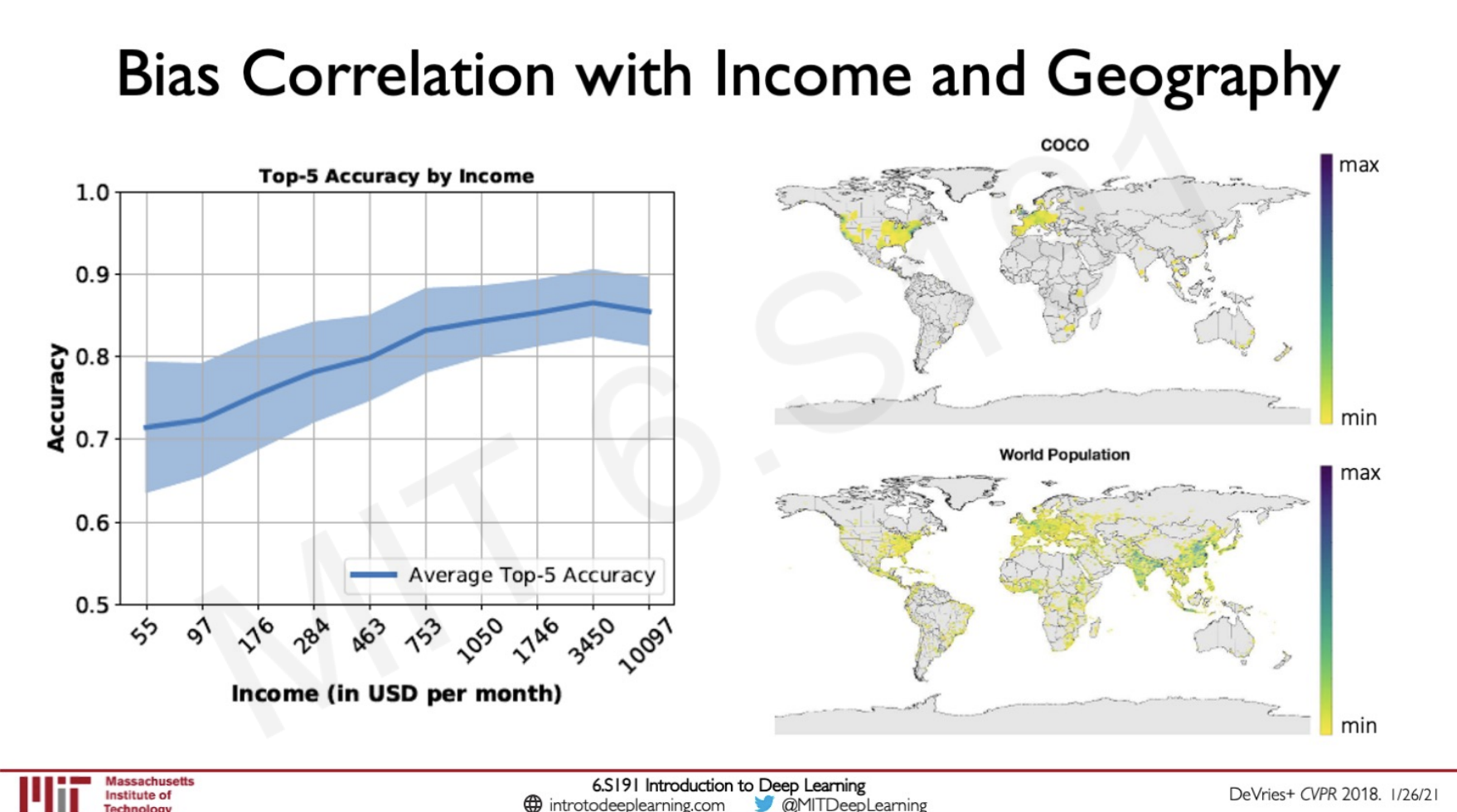
This is because the test images that were taken were taken from houses with a greater income but machine learning models should be representative looking at the regions of the world in the right side of the image we can see that these images were taken from not the countries with the most population of people and hence the data is biased so the models also will be biased. Most of the models that are deployed in real life are similar to this even though it has claimed that deep learning has solved such problems as the vision it may not be always true because of these biases.
Bias at All Stages of the AI Life Cycle
- Data imbalances with respect to class labels, features, input structre
- Model lack of unified uncertainty, interpretability and performance metrics
- Training and deployment feedback loops that perpetuate biases
- Evaluation done in bulk, lack of systematic analysis with respect to data subgroups
- Interpretation human error and biases distrot meaning of results
Understanding and Mitigating Algorithmic Bias

Taxonomy of Common Baises
There are mainly two categories of biases in Deep Learning they are
1.Data-Drive
These are bias in deep learning that occurs due to the data that is used to train the model
1. Selection Bias
Data selection does not reflect randomiation
2. Reporting Bias
What is shared does not reflect real likelihood
3. Sampling Bias
Particular data instance are more frequently sampled
2. Interpretation-Driven
These are bias in deep learning that occurs due to how we human beings interpret the data.
1. Correlation Fallacy
This is miss-interpreting correlation for causation.
2. Overgeneralization
"General" conclusions drawn from limited test data
3. Automation Bias
AI-generated decisions are favoured over human-generation decisions.
Even though we can categorise biases as such truly they are all correlated and understanding them one by one would help us understand the correlation and also solving some of them could actually help in solving the other.
Interpretation Driven Biases
Bias from the Correlation Fallacy
Let us say we are trying to build a model that predicts the number of given Phd's given in any given year, and we find a variable (red) that is very correlative to this and we start building the model but just because the data is correlated does this means that the model is learning the ground truth. The data represented in red is actually the total revenue generated by arcades in every year this is correlated but this does not mean that we can make a model out of this because we neural network that we are building is not looking for pattern of Phd graduates it is looking for something else, the ground truth is miss-represented.

Bias from Assuming Overgeneralization
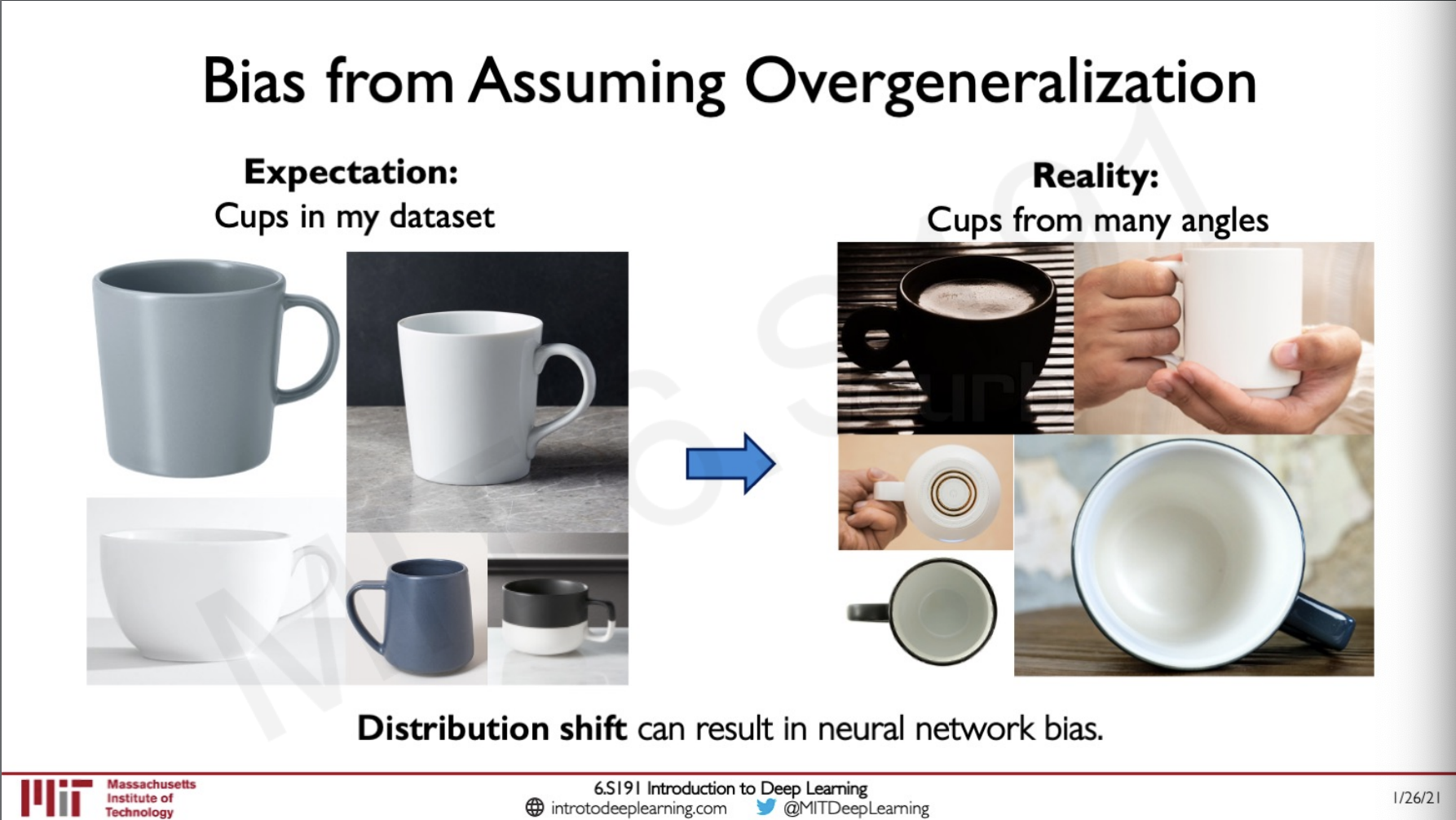
Bias might also happen due to overgeneralisation in the dataset, the cups i the left are too generalised because of the same angles this causes a distribution shift because in real life there cups can be from any angles like what is shown in the right.
One approach to solving dataset with distribution shift that was done was to construct the test dataset accounting for already identified distribution shifts.

In the case above the distribution shift happens with regard to the location and time.
But in case of something like medical data this means sourcing data from different hospitals for test and validation set.

Biases due to Class Imbalance

Given the following scenario what would be out Model Accuracy ? would it represent the class with frequency in reality or the frequency in the data. Obviously as we know the data would not be representative of the data in the real world because the model is trained based on the data in the dataset and this would be reflected in the model as well but the problem is since this is not representative of the real world our model is going to be biased.
The way to solve this is by actually balancing out all the classes to be equal this should make our model accurate.

How does this cause this imbalance the learning process ?
Well let us consider that we have a classifier with orange and blue representing the data-points and we are training this the update steps work in such a way that this would move the function a small step closer to the new point every time but the catch is here our data is imbalanced in such a way that orange: blue is in the ration 1:20 what this means is that for every orange point there would be 20 blue points which would result in the learning also being imbalanced since there is not much step taken by the classifier towards the orange points due to the only incremental updates in each step.

The effects of this can also be observed in real world, how does the data get miss-represented ?

Let us consider medicine when we consider MRI scans of the brain here the ratio of people having cancer to the total population is very less this ratio will reflect in the dataset as well so this means that we need to alter the dataset in such a way that we can have equal number of images for both cases.
If the data is balanced the learning process will also be balanced.
Some techniques to balance data is by assigning weights to each of the classes according to there frequency so that the resulting contribution is balanced.
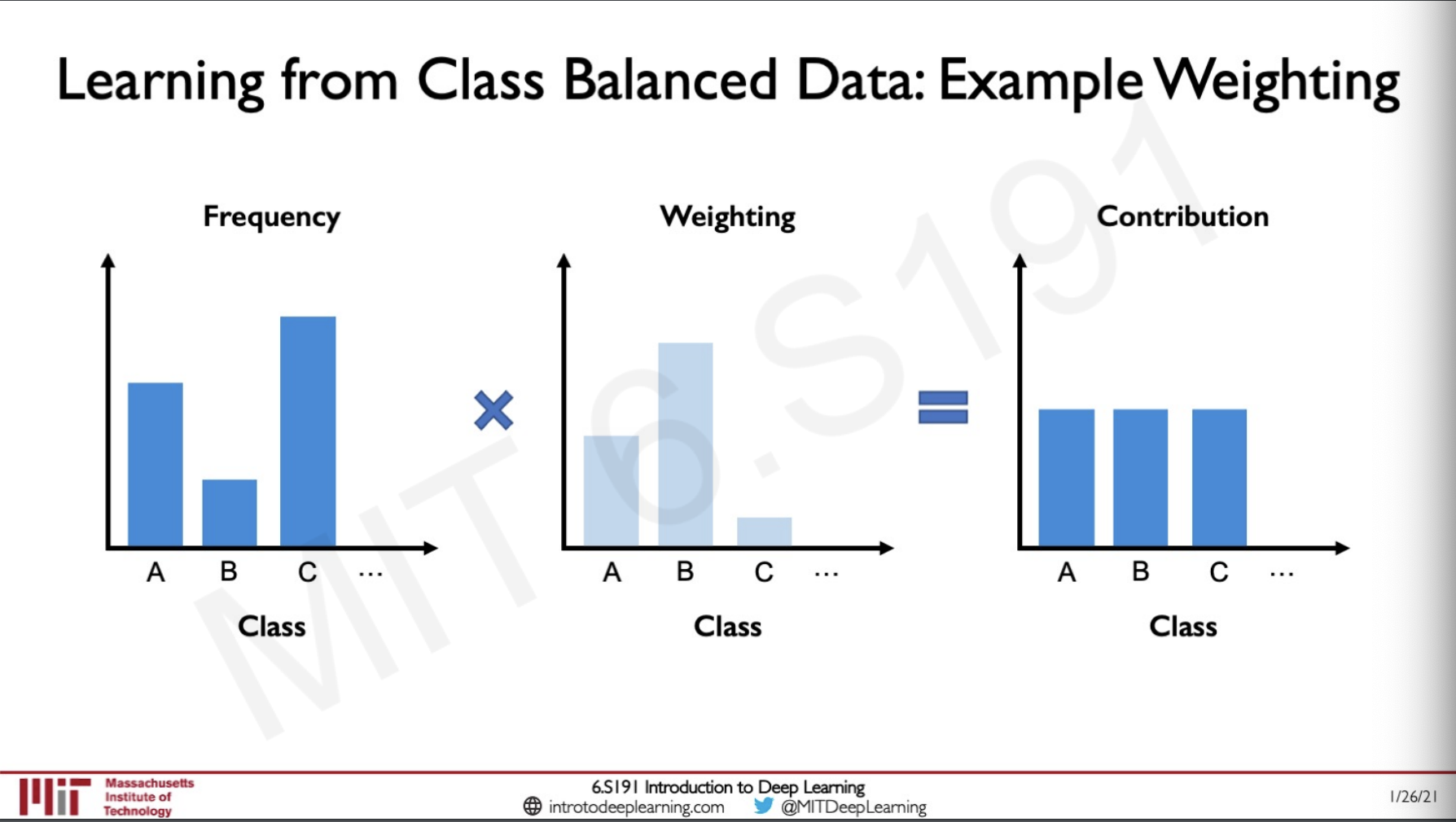
We can visualise this in such a way that if there is a datapoint that has less number the dataset then it can occupy more size so that the frequency of them being taken is increased.

Biases in Features
Bias can even happen in the case of features even if we have a balanced class there could be potential bias in the data feature itself.
Let us consider some scenario,

Here we can see that the real-world data has mostly people with black hair but the golden standard that is used in production shows blonde and brown hair over-representation. But in both cases the read hair is underrepresented but we want our model to recognise the same so a balanced dataset would have all 4 categories in the same amount.

Now the question is how can we uncover such biases in a learning pipeline itself and how can we mitigate such biases if they exist.
Learning Techniques to Imrove Fairness
Bias Mitigation
In this technique we take the dataset of the model that is biased and remove the problematics signals from them and this would result in mitigated bias improving fairness.
Inclusion
In this technique instead of removing data we add more signals to the desired features which would re-weight signal and improve fairness.
Bias and Fairness in Supervicsed Classification

Some of the ways we can evaluate these bias are by a disaggregating evaluation which makes us test the performance with respect to different subgroups in the dataset.
Another method that is known to work is Intersectional evaluation which is evaluating performance with respect to subgroup intersections.
Adversarial Multi-Task Learning to Mitigate Bias
This method was used in a language model to de-bias its effects.
For this first we need to specify the attribute for which we are planning on mitigating the bias.
This is represented as z.
There are generally two discriminators in this case one to do the task and another to get our sensitive attribute z.
The model is trained adversarially and a negative gradient is given back to mitigate the effect of z on the task decesion.

The performance of this model was checked in both biased and debiased cases and the result was fascinating.
When the model was tasked to complete the analogies for what he is too she as a doctor is to for the biased model the model said nurse, nanny and so on whereas in the de-biased model it said paediatrician, dentist, surgeon etc. What this means is that the model is giving synonyms of the word doctors which shows the effect of debiasing.
Adaptive Resampling for Automated Debiasing
We have also seen some methods to debias models by using automated methods to learn distributions that were being overrepresented and underrepresented and generate debiased images that can be used for training the model.
Mitigating Bias through learned latent structre
How this works is by first learning the latent structure, from the learned latent structure we can understand the distribution and see what are the feature that are over represented and underrepresented.

From the probability distribution we can adaptively resample the data which would be a debiased dataset which can then be use to create models that can be used to new fair data distribution.
The math behind this looks like this,


Adaptive resampling has the advantage of not having to specify the features we are debiasing against this is especially useful because there might be features that are in the dataset which we are not about but would be doing some form of bias or if we humans are specifying what to debiase against there might still be chances that we are imposing our bias on the model.

The evaluation does by researchers at MIT shows that as the debiasing increased the accuracy of the models as the debiasing rate increase.
Debiasing is very important in keeping the model representative of the data.
Summary

Sources
MIT introtodeeplearning : http://introtodeeplearning.com/
Slides on intro to deep learning by MIT :
http://introtodeeplearning.com/slides/6S191_MIT_DeepLearning_L8.pdf
Subscribe to the newsletter
Get emails from me about machine learning, tech, statups and more.
- subscribers