Part 1 : Learning Hands-on Machine Learning with Scikit-learn Keras and Tensorflow


Abhijit Ramesh / February 21, 2021
22 min read • ––– views
The Machine Learning Landscape
In this series of blogs, I would be writing my notes while I am learning from the book Hands-on Machine Learning with Scikit-Learn, Keras and Tensor-flow. I keep notes for everything I learn so that it is easy for me to come back to something and re-learn it. The way I think of it our brain works by connecting related memory and thoughts we have when we encounter some new topic and we understand most of the new concepts by focusing on what we already know. My notes generally contain these thoughts, examples that pop into my mind and also the code I write in case of CS-related topics, mainly Machine Learning. Generally, my notes are sitting in one corner of my notion document which is accessible to me and some of my friends who are reading the same book so that we can have some discussions and learn more but I realised since my notes are being helpful for them to revise as well why not make them public and hence this series of blogs.
In this series of blogs, I would be learning Hands-on Machine Learning with Scikit-Learn, Keras and Tensor-flow. If you would like to follow along purchase the book from here if you haven't already. I would not be writing the contents from the book here I would only be writing down my notes so please refer to the book alongside to get a better understanding.
Preface
Machine learning has been around for a long time, we just don't really realise it is the same technology that today powers all that cool youtube recommendations that we get while watching youtube videos or those scary ads we get while surfing ahmm you which social media and probably in the future would create robots that can think like humans. The spams filters in our emails are one kind of such machine learning. Thinks as OCR have existed for a long time. The first time I came across and realised it was machine learning was when I played this game akinator which completely blew my mind, The game is basically to think of someone famous and then answer a couple of questions with yes-no-maybe and the game predicts who the person it. I was soo curious that I googled what it was and came across decision trees which obviously did not make sense to me post-computer science education so I had to google that as well and came across machine learning and the whole idea that if we combine some math and algorithms we could make a computer think like a human was very fascinating to me.
What is Machine Learning ?
Machine learning (ML) is the study of computer algorithms that improve automatically through experience. It is seen as a part of artificial intelligence. Machine learning algorithms build a model based on sample data, known as "training data", in order to make predictions or decisions without being explicitly programmed to do so.[2] Machine learning algorithms are used in a wide variety of applications, such as email filtering and computer vision, where it is difficult or unfeasible to develop conventional algorithms to perform the needed tasks. ~ Wikipedia
Generally, we need to explicitly program machines to do some task lets say like given a list of twitter handles who have liked your latest tweet. But machine learning is a different approach to this like if we are given the data of our tweets and people who like our post we write algorithms to learn from the pattern here and give predictions such as who are mostly likely to like my next tweet. Here we don't have to explicitly program the computer to perform this task but write algorithms that learn from some given data.
Spam filters are another example where we flag a email based on some keywords that appear frequently on spam emails. In the training data of spam emails we call the malignant emails spam (obviously) and the benign emails ham.
I have made a spam filter using federated learning while reading Grokking Deep Learning.
Why Use Machine Learning ?
In order to understand this we need to think of how we would approach a normal programming problem or Software 1.0 (traditional programming) and then compare it with Software 2.0 (machine learning).

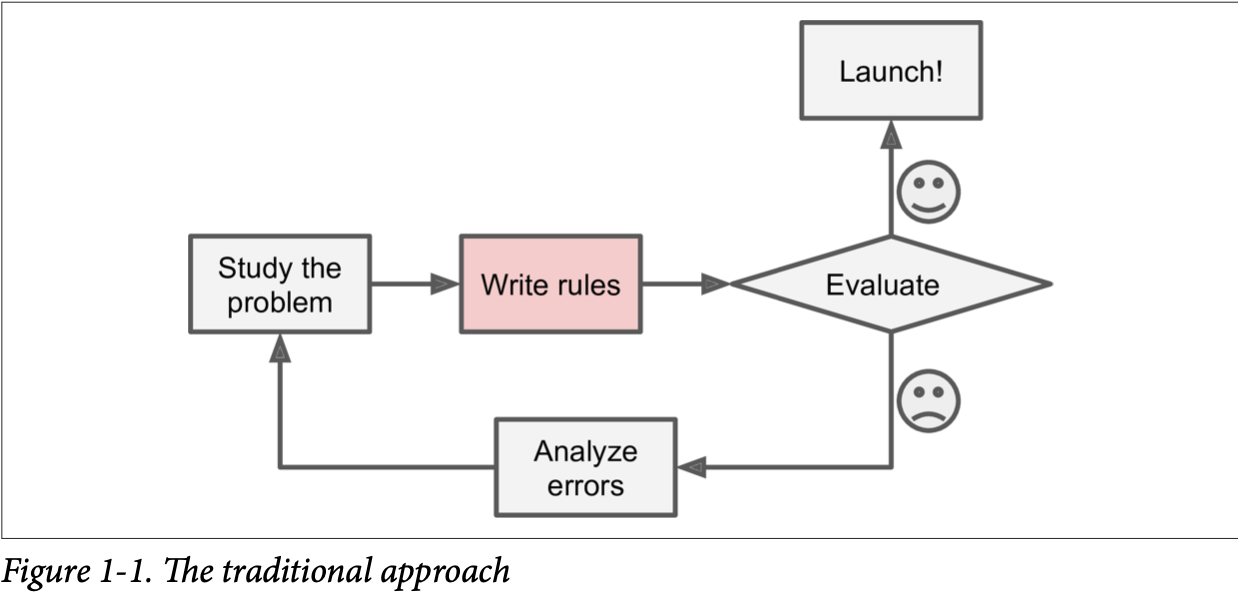
Let us consider our example of twitter likes, If I need to predict who is going to like my tweet, I first need to categories my tweet according to different topics based on keywords on my tweet and then figure out what people are mapped to these topics.
For this, I need to write a detection algorithm for each of the classes and then map this to the people who generally like the post of that category. I have to keep on doing this until the results are good enough. Thinking about this itself is making me nauseated.
Since the problem here is not trivial my program is going to be a lot of complex rules which will take a long time to run. But instead, I could follow a machine learning approach.
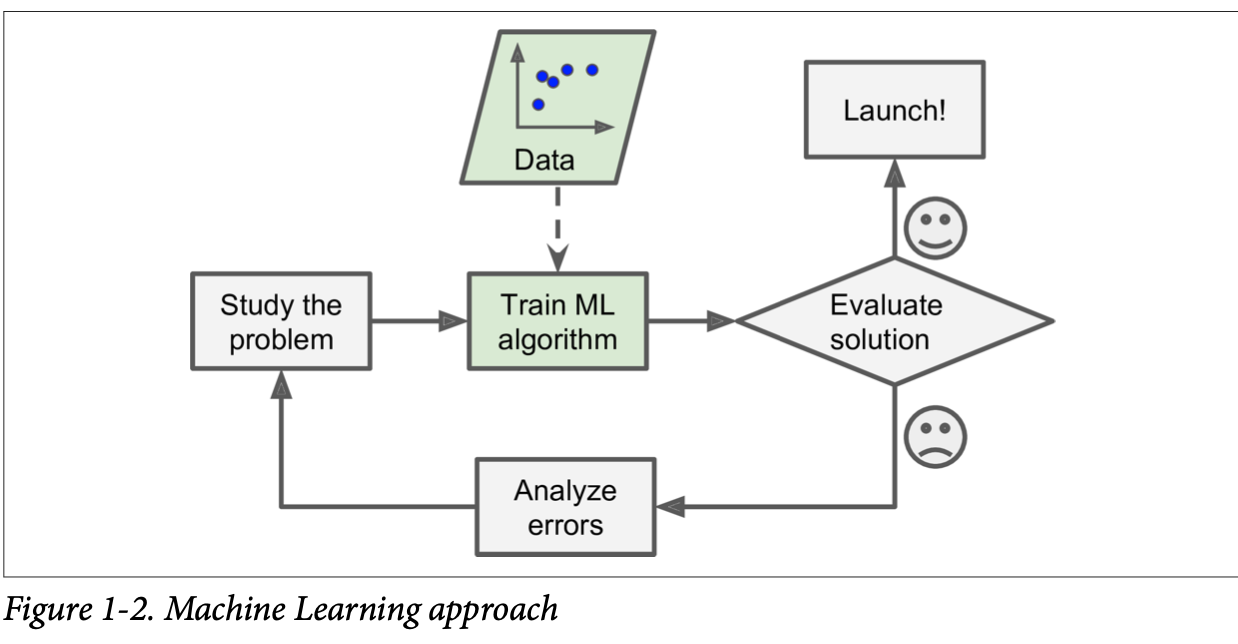
I have the data of my previous tweets, I could find a machine learning model which could easily fit this data and then use the same to predict for my future tweet. The benefit here is If I write a new tweet that does not fall under any of the categories I have previously programmed using the Software 1.0 approach to work with this problem I have to write a new role to accommodate the same. While a machine learning algorithm could learn to adapt to the new pattern.
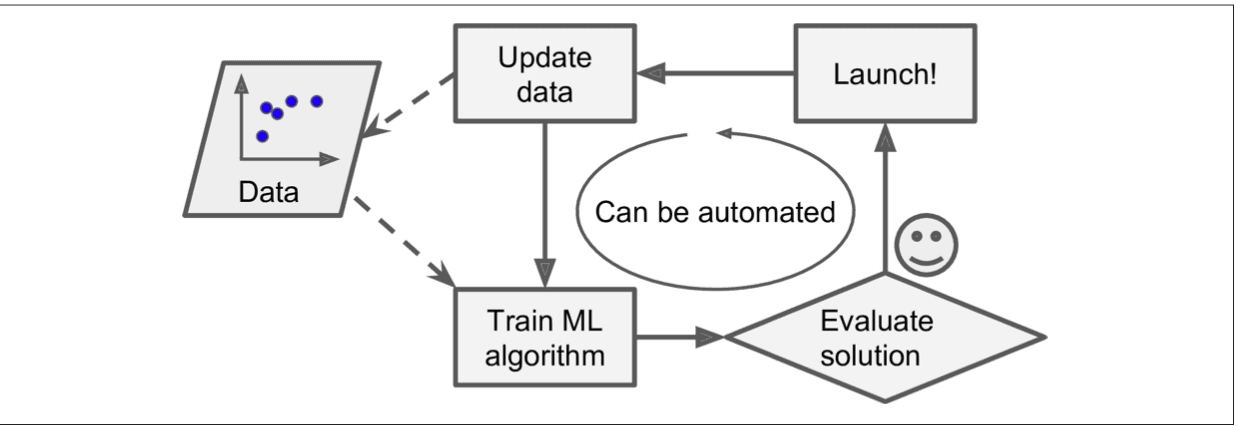
Machine Learning also has a clear win when it comes to problems where traditional approaches are too complex or there are no algorithms developed yet for the same. Thinks like speech recognition or character recognition which we can train for two or more samples but if we think about scaling the same for millions of samples the problem becomes out of hand and we need to write an algorithm that learns by itself. Also if you are thinking of technology singularity where humans are overtaken by AI overloads you better be ready for this, humans learn from machine learning as well. After training a model and then testing it we could take a look at the underlying data and understand patterns which was not apparent to us initially cool right ? This is called data mining.
Types of Machine Learning Systems
We can categorise the type of machine learning system that is being used based on several question.
If they need human supervision while being trained depending upon the answer they could be Supervised, Unsupervised, Semisupervised and Reinforcement Learning Models.
If they can learn incrementally on the fly upon the answer they could be online or batch learning models.
If they work by simply comparing new data points or they detect patterns in training data? This could be an instance-based or model-based learning.
It is not really necessary that these criteria must be met on point and it is always the case that a it should be just one of these categories. It could also be that we could combine these techniques a SOTA implementation might most of the time have something that could be learning on the fly as well as a supervised learning system.
Supervised/Unsupervised Learning
This category is classification of models based on amount and type of supervision they get when they are trained.
- Supervised
- Unsupervised
- Semi-Supervised
- Reinforcement
Supervised Learning
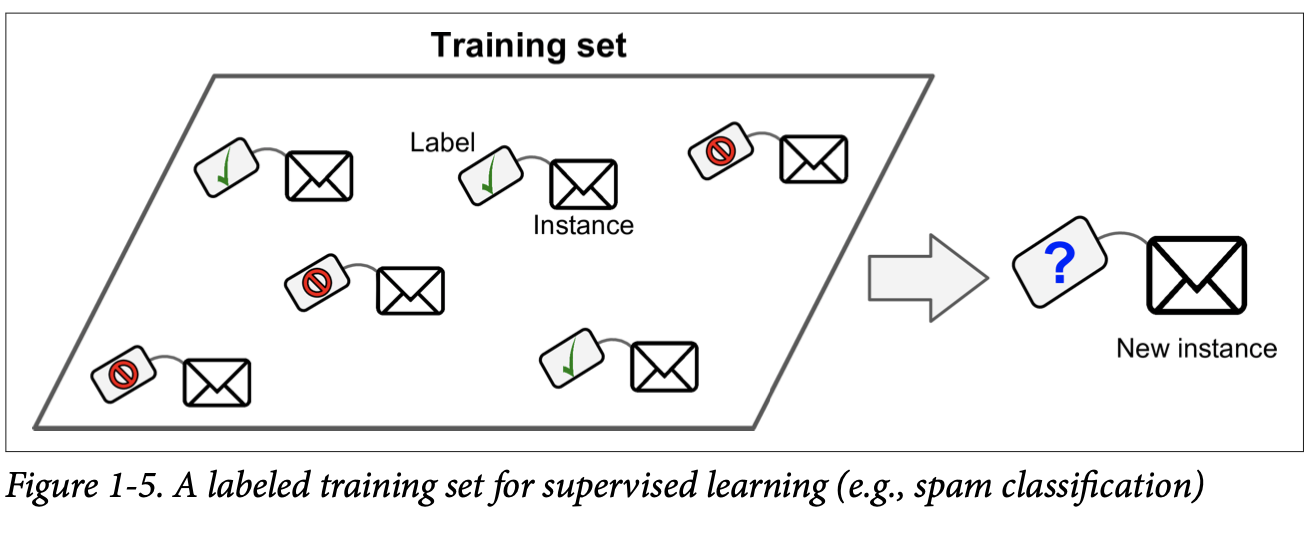
These algorithms are given training data along with the desired output which are called labels during there training phase. Generally, a model which is trained for such a task is used for classification where we have one data and we need to tell what category this data falls under like benign or malignant. There is also regression where we need to predict a target numerical value given a set of features such as specifications of a car and the task is to predict the price.
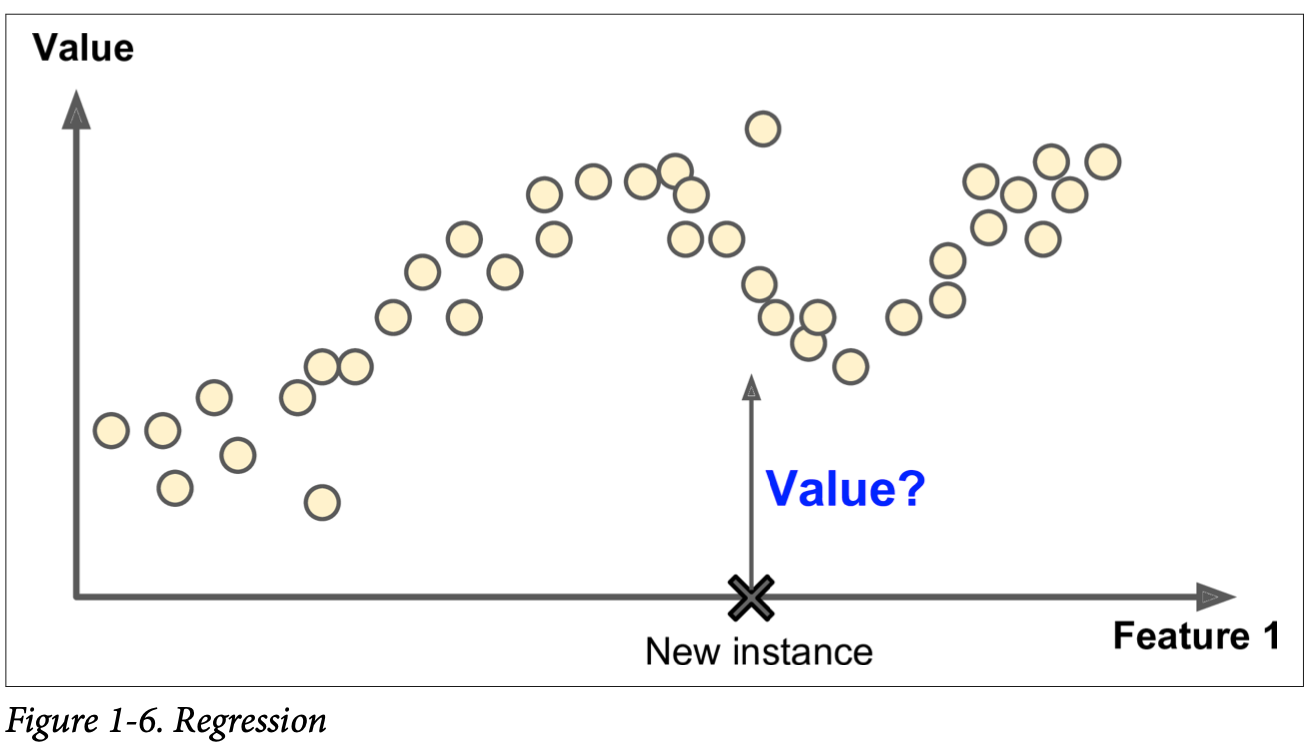
Some regression algorithms are used for classification and vice versa. Logistic Regression is used for classification as well even thought the name has regression in it.
Some supervised learning algorithms are,
- k-Nearest Neighbours
- Linear Regression
- Logistic Regression
- Support Vector Machines
- Decision Trees and Random Forests
- Neural Networks
Unsupervised Learning
What if the training data is not labelled, the system will learn on its own this is unsupervised learning generally this is done by clustering.
Clustering
- K-Means
- DBSCAN
- Hierarchical Cluster Analysis
Anomaly detection and novelty detection
- One-Class SVM
- Isolation forest
Visualisation and dimensionality reduction
- Principal Component Analysis
- Kernel PCA
- Locally-Linear Embedding
- t-distributed Stochastic Neighbour Embedding
Association rule learning
- Apriori
- Eclat
These are some common unsupervised learning algorithms.
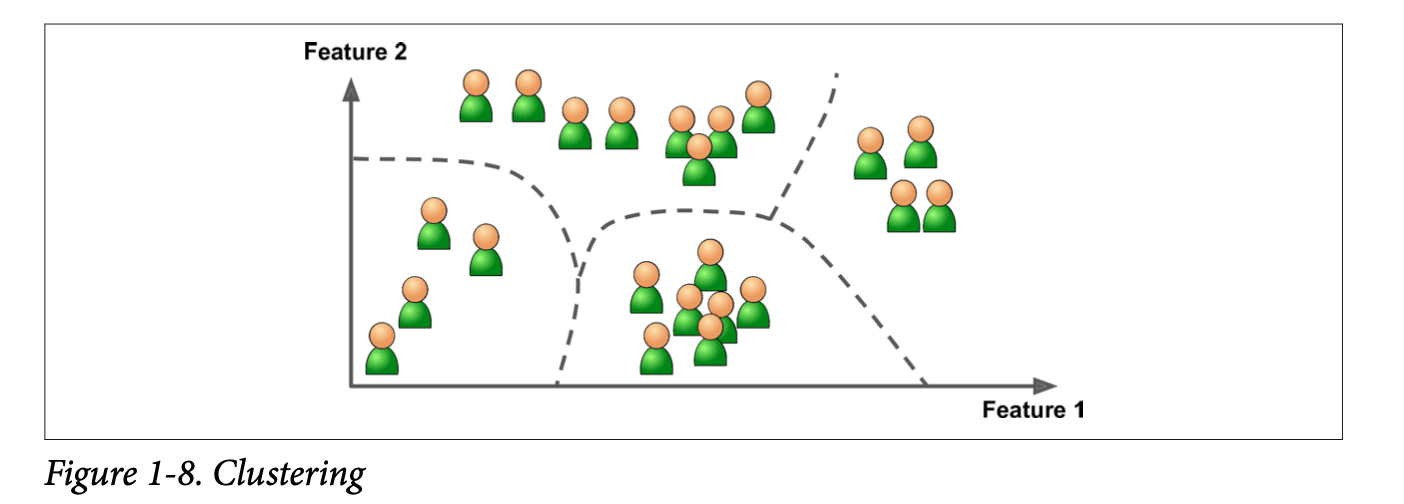
If we want to group a lot of data we generally do clustering for example when we have to group people visiting our blog site. We don't have to explicitly tell the algorithm what to look for but it will find insights like 40% of young visitors who do web development visit my blog site during the evening or 20% working professionals visit my website during weekends. A hierarchical clustering algorithm even subdivided each group into smaller groups.

Visualisation algorithms are especially useful for identifying unsuspected patterns or reducing the dimensionality, If we have a data we can simply it without too much information by correlating features into one. These algorithms output a 2D or 3D representation of our data.
Anomaly detection is an instance of unsupervised learning where the task it to detect things like unusual credit card transaction or removing outliers from dataset before feeding to a learning algorithm.

Rule learning is an application where the algorithm digs into a very large dataset and try to figure out patterns in them. Things like while doing a purchase in amazon we get recommendation saying people who have bought this item have also bought so and so item.
Semisupervised Learning
This is mostly a combination of supervised and unsupervised learning models and most of the time the unsupervised is more than the supervised part for example google photos clusters people that are found in many photos and then ask us to simply label the name in one photo it will automatically do the indexing for the rest of the images with the same label. So these are basically datasets which are partially labeled.
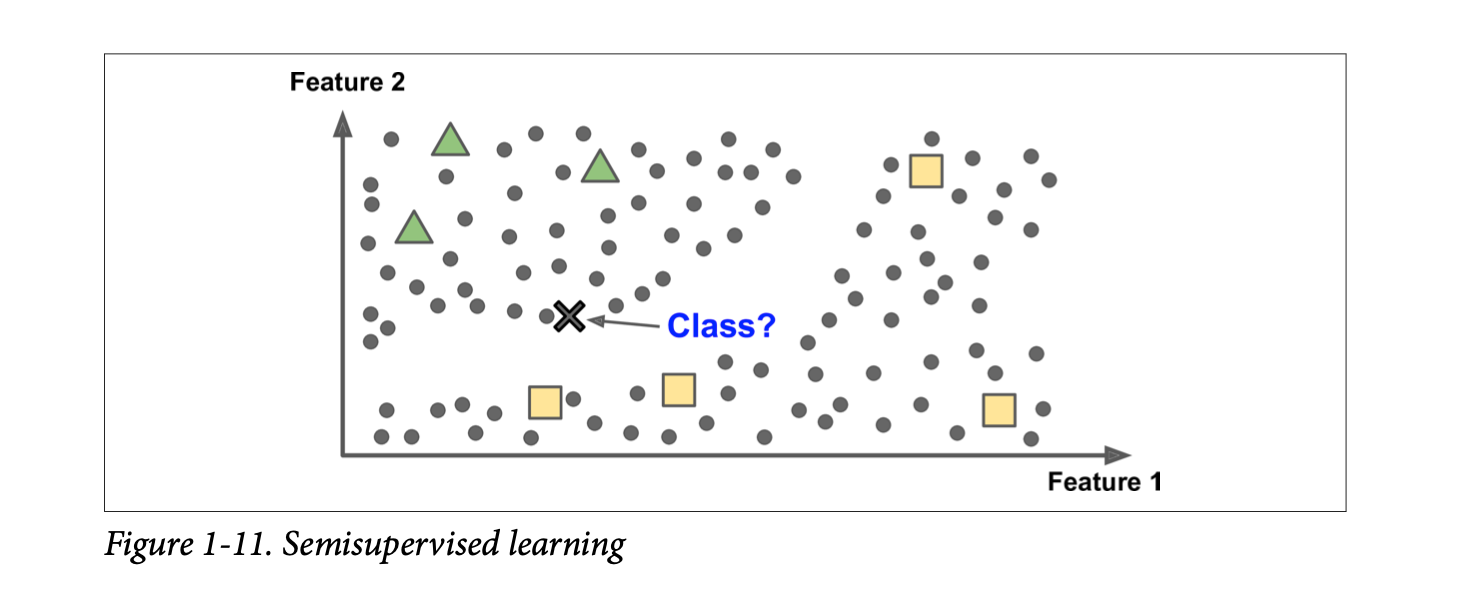
Reinforcement Learning
This is a very neat method where the learning system (agent) can observe the environment and then select and perform actions to get reward and with the help of this reward the agent figures out the best policy or strategy to maximise the reward to do a particular task.
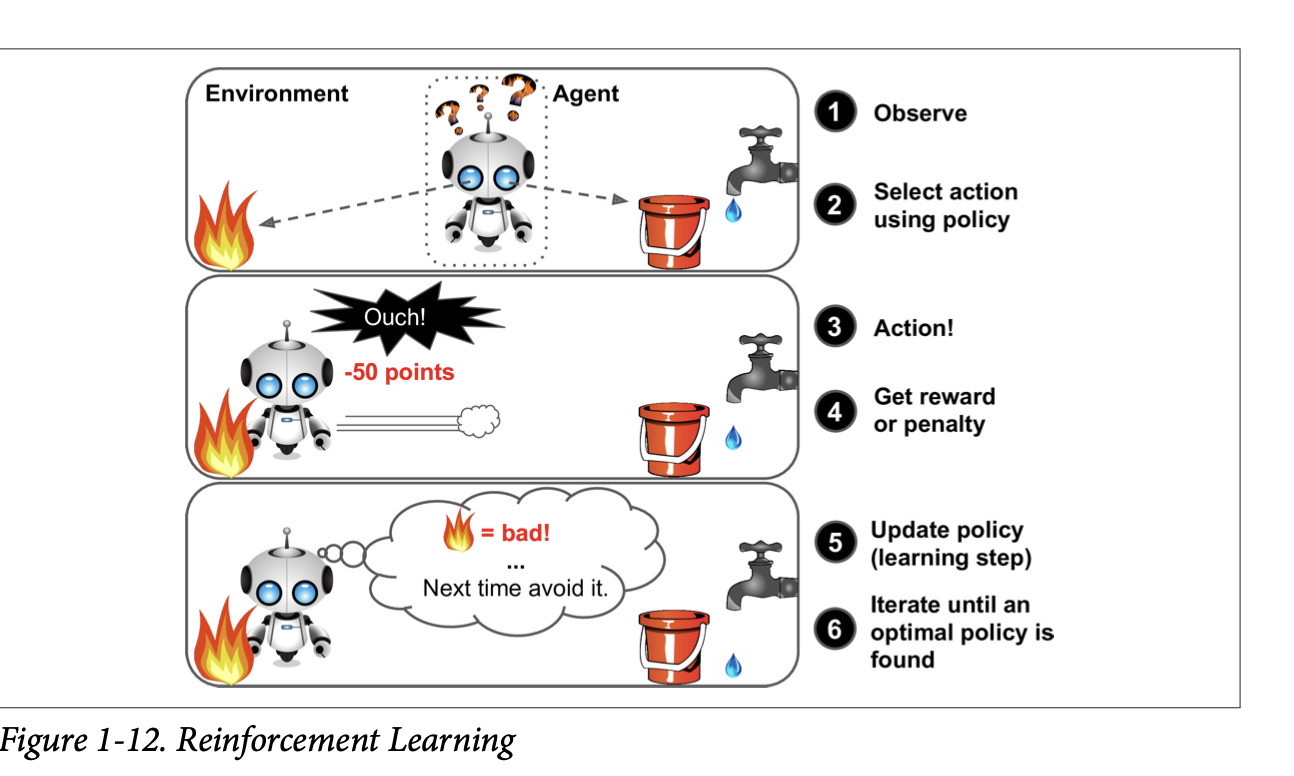
All those cool game playing or chess playing AI videos in youtube we see are examples of Reinforcement Learning.
https://www.youtube.com/watch?v=kopoLzvh5jY
Batch and Online Learning
This classification is done based on how systems can learn incrementally form a stream of incoming data.
Batch Learning
Here the system does not learn incrementally rather training is done using all the available data at once. This will might take a lot fo time and computer by once the training is done the model is deployed in production where it will server do inference.
When the data is updated we will re train the model and replace it in production.
These kind of models are very common and are generally used as well. Generally, they are updated on a daily or weekly basis only that they take up a lot of time and computer to do this update even though they can be automated and generally does not need any kind of human intervention once it is deployed.
But if we have very limited resource this is generally not a good option so we need to go with online learning.
Online Learning
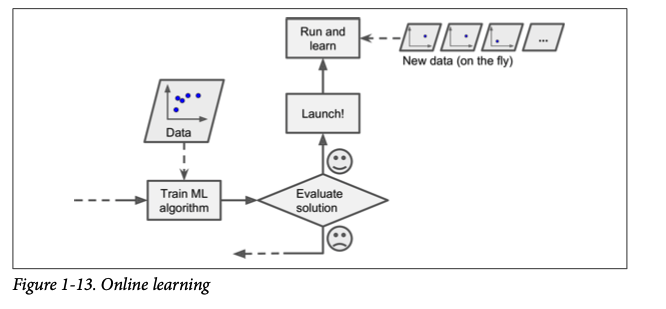
In this learning data is generally divided into mini batches and served as chunks or sequentially to the model. Each learning step is faster and cheap so the new data can be included in the update the model gradually. This is good for systems that receive data in a continuous flow and can adapt to change rapidly. If we don't have to save a previous state of the model we can always save a lot of space and discard the old dataset.
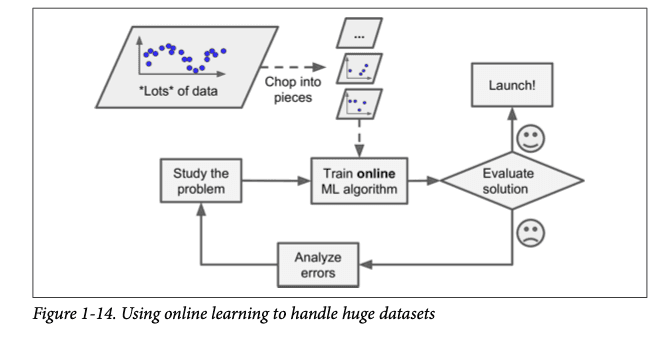
Out-of-core is kind of a variation of online learning; sequential learning to be clear because this is done offline. There might be a huge dataset that cannot be generally trained on a model which cannot fit a very huge dataset the algorithm takes part of the dataset and runs training on that and then repeats the process until it has run on all of the data.
Instance-Based and Model-Based Learning
The way we determine if a model is good or bad is by seeing how well the model performs in validation data. This is called generalisation. Validation data is a different form of test data it is not involved in the part of the training even for calculating the error this is unseen data for the model. The model performing well on test data and train data is good but the real challenge is how does it perform on validation data that is the unseen data. If we classify machine learning based on any of these approaches it would be Instance-based or Model-based learning.
Instance-based learning
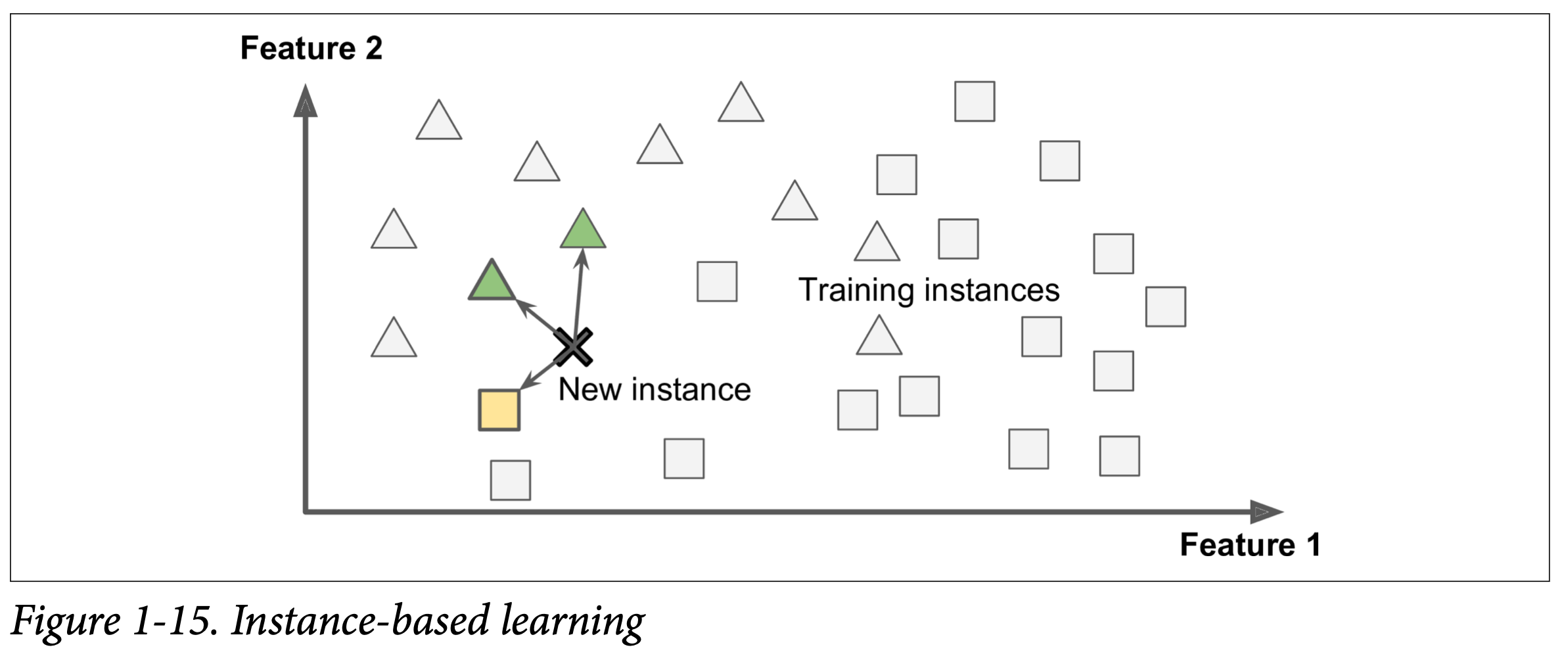
When we humans learn something that is the easiest way to learn it. Well, by-heart it this is probably how we started learning in kinder-garden. I was always bad at by-hearting stuff, to date, I don't know most of the multiplication tables. So the idea of instance-based learning is the same, it learns things byheart. It would have some form of similarity measure like the shape of the object or the size of a text file or something like that and it compares new instances with the same similarity measure learned from the similarity measure.
Model-based learning
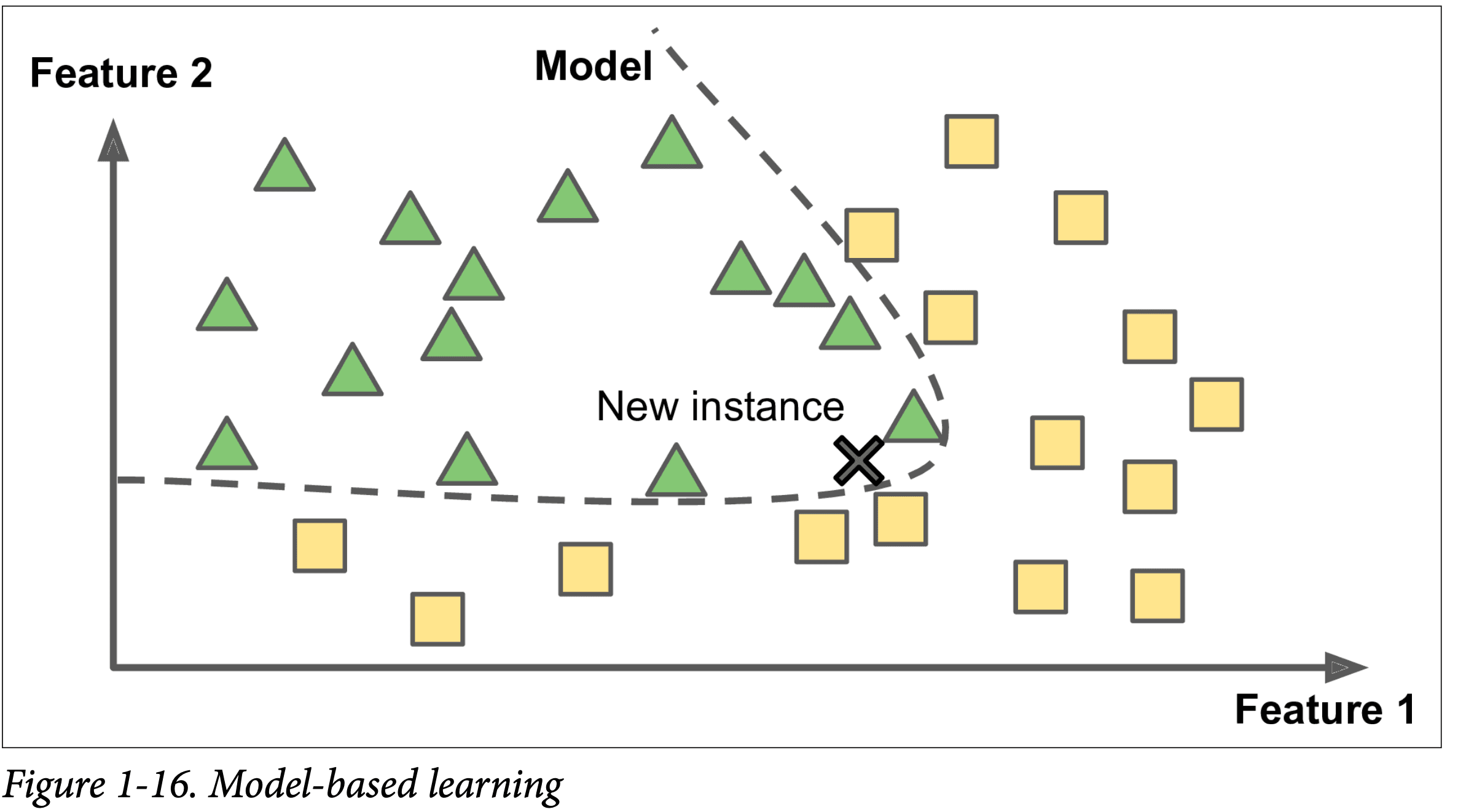
Models based learning is what we are most familiar with make a model using some examples and then give it new data and ask it to predict the output.
Lets check this out in code
First, we need to download the dataset from OECD's website and IMF's website but I am not going to do that since I can simply wget from GitHub repo of handson-ml2.
!wget https://raw.githubusercontent.com/ageron/handson-ml2/master/datasets/lifesat/gdp_per_capita.csv
!wget https://raw.githubusercontent.com/ageron/handson-ml2/master/datasets/lifesat/oecd_bli_2015.csv
Once we are done with this step we need to join the data together and sort it by GDP per capita.
def prepare_country_stats(oecd_bli, gdp_per_capita):
oecd_bli = oecd_bli[oecd_bli["INEQUALITY"]=="TOT"]
oecd_bli = oecd_bli.pivot(index="Country", columns="Indicator", values="Value")
gdp_per_capita.rename(columns={"2015": "GDP per capita"}, inplace=True)
gdp_per_capita.set_index("Country", inplace=True)
full_country_stats = pd.merge(left=oecd_bli, right=gdp_per_capita,
left_index=True, right_index=True)
full_country_stats.sort_values(by="GDP per capita", inplace=True)
remove_indices = [0, 1, 6, 8, 33, 34, 35]
keep_indices = list(set(range(36)) - set(remove_indices))
return full_country_stats[["GDP per capita", 'Life satisfaction']].iloc[keep_indices]
oecd_bli = pd.read_csv("oecd_bli_2015.csv",thousands=",")
gdp_per_capita = pd.read_csv("gdp_per_capita.csv",thousands=",",delimiter='\t',encoding='latin1',na_values="n/a")
country_stats = prepare_country_stats(oecd_bli,gdp_per_capita)
X = np.c_[country_stats["GDP per capita"]]
y = np.c_[country_stats["Life satisfaction"]]
This should give us something like this table if we print out the head()
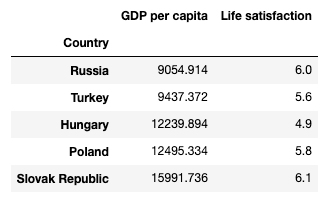
Now we can visualise this dataset so try and understand some trends and make some intuitions.
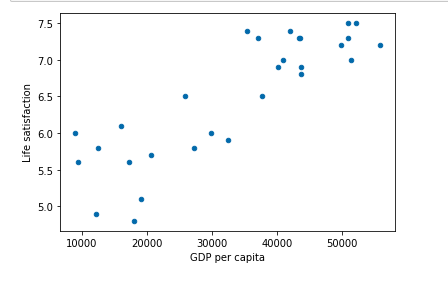
As GDP per capita increases Life Satisfaction seems to increase maybe after all money does make people happy.
Here we can see the trend is linear and hence we could choose a linear model like linear regression.
model = sklearn.linear_model.LinearRegression()
This model will have the following function,
$life_satisfaction = \theta_0 + \theta_1 \times GDP_per_capita$
We can simply change values for $\theta_0$ and $\theta_1$ to fit the model.
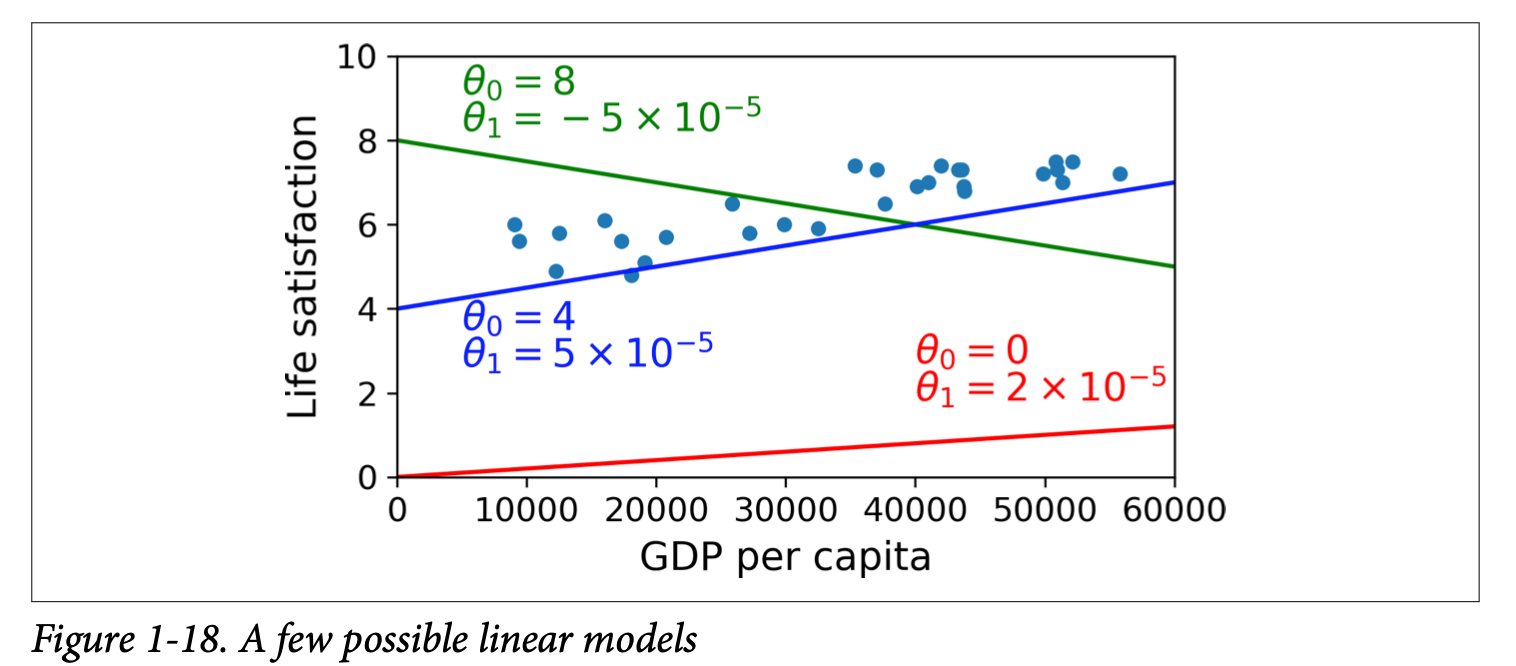
We would not be doing this manually but instead we will be using a fitless function that measures how good the model is or define a cost function to see how bad the model is here we will be having a cost function since we are going with linear regression and the distance between the linear models prediction and the training example would be the cost which the models job is to reduce.
Let's fit the model in the training data.
model.fit(X,y)
Now we need to find the life satisfaction for Cyprus but we don't have the data in our dataset this is totally cool since we have just build a model which can predict exactly this.
X_new = [[22587]] # Cyprus GDP per capita
print(model.predict(X_new))


Let's try this out with instance-based approach as well, here I want to use k-nearest neighbours
model = sklearn.neighbors.KNeighborsRegressor(n_neighbors=3)
model.fit(X,y)
X_new = [[22587]] # Cyprus GDP per capita
print(model.predict(X_new))
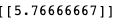

Here we see that Slovenia has a GDP per capita close to what we gave for Cyprus and hence the KNN algorithm gave a similar life satisfaction for the same or it could be that the average of Portugal, Spain and France also give around 5.77.
Steps to fit a data
- Study the data
- Select a model
- Train the model on training data
- Apply the model to make a prediction
Main Challenges of Machine Learning
Honestly there are only two things that could go wrong from the above steps the two things that we have to do ie.. choosing a bad algorithm or having a bad data.
Insufficient quantity of training data
Machine learning is not yet as advanced as us humans we can learn something looks some way by just seeing one more more examples but for machine learning you generally need thousands of examples just to train a small network and if you want to train a model for a very complex problem you need millions of samples.
The Unreasonable effectiveness of data
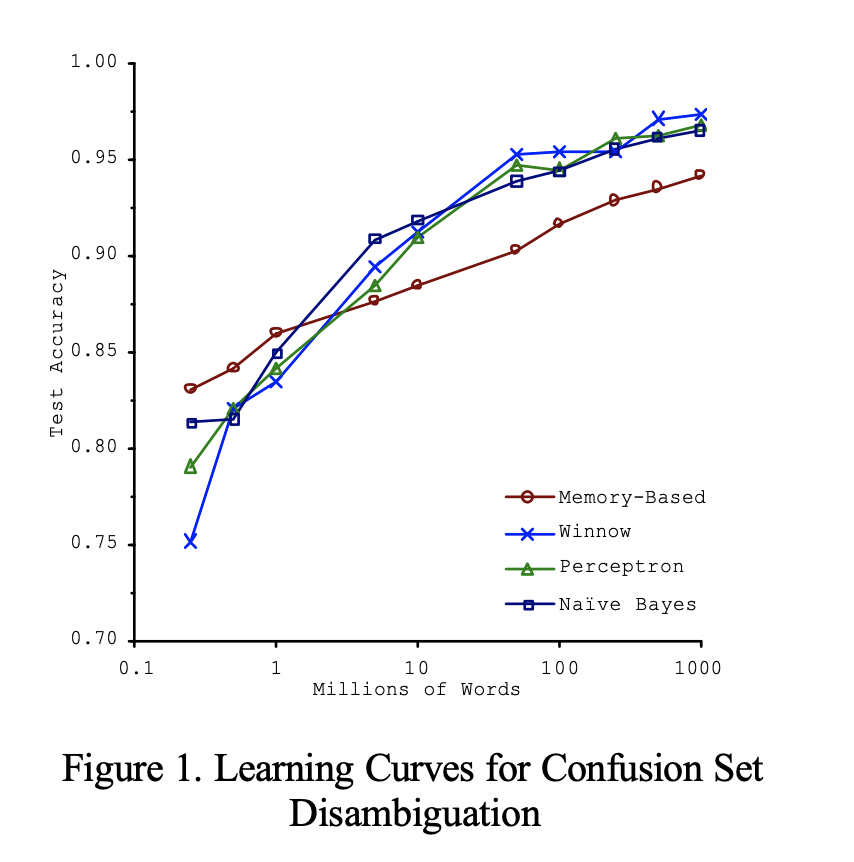
This figure shows a comparison of different machine learning algorithms and it performs fairly similar given enough data. This figure is taken from this paper scaling to very very large corpora for natural language disambiguation. This just says that we have to spend more time and money on developing corpus rather than algorithms. In reality, it is not very easy to get such refined training data with millions of sample so we cannot abandon the algorithm just yet.
Nonrepresentative Training Data
If we add some new data to the model it is very important that our model adapt to this new changes and learn to generalise well.
If we add some more countries to the linear model which I did earlier probably it would not generalise as well, some rich countries are not happier than moderately rich countries and some poor countries seem happier than many rich countries.
If the sample is too small we will having sampling noise which is non-representative data as a result of chance, even large samples can be non-representative if the sampling method has some error this is called sampling bias.
Poor-Quality Data
Most data scientists spend most of their time fixing the data set than selecting a good model. This is because if the data is full of errors, outliers and noise the model would not be able to recognise useful patterns that are present in the data. If there are missing values for some features we just decide theatre we want to ignore this attribute or ignore the instance altogether. If we are not sure how this would affect the model performance what we can do is train one model based on the attribute and one without this would show us how relevant a particular data is.
Irrelevant Features
The data we are mostly training on would not be collected with the particular use case in mind so there might be lot of irrelevant features in the data which we would probably not end up using these features or if we did it might even give unexpected results. Here we do feature engineering,
- Feature selection : selecting the features which actually contribute to the pattern we are looking for.
- Feature extraction: combining features in the dataset to produce a more useful one.
Overfitting the training data
If our dataset is too small or is our training data is too noisy the model will actually start learning those noise compared to signal (useful pattern). This is a very common issue with machine learning models they will by-heart the training data and when they are presented with a new data which it has never seen before it would give a wrong prediction. We want our model to generalise rather than by-hearting noise.
Constraining a model to avoid overfitting is called regularization.
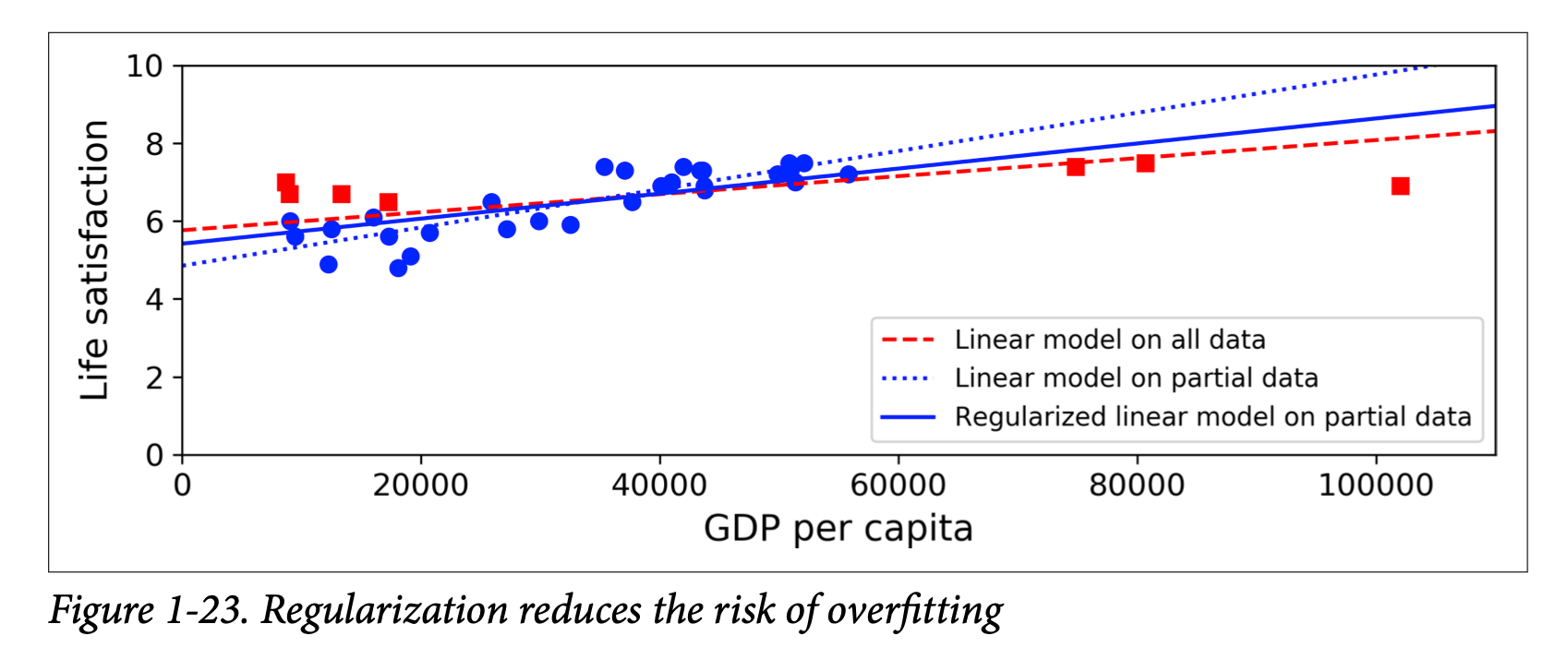
Here the regularisation applied to the model is basically forcing one of the degree of freedom to be 0 which would make the model have one degree of freedom and would take long time to fit the data but would avoid overfitting. Regularisation made the model have a smaller slope.
The amount of regularisation done by the model can by controlled by controlling the hyper-parameter.
Underfititng the training data
Deep neural networks are wicked in detecting complex underlying patterns but this is not the same for simple models they may not be able to learn underlying structure of the data we can fix this problem by
- selecting a more powerful model, with more parameters.
- Feeding better features to the learning algoritham
- Reducing the constrains on the model
Testing and Validating
Even though we can design a lot of cost functions or error functions to figure out how we want our model to perform in reality the best way to figure out how it is performing is to either put it out in production and see if it is working as required or split the data into two parts one is the test data and another is the training data. The model during training can use the training data to optimise the weights but after training it can use another set of data called test data to is we are getting good results we call the error rate here as generalisation error. If the training error is low and the generalisation error is mode obviously our model is overfitting.
Hyperparameter tuning and model selection
Let's say we have two models which perform well on the dataset we have now we need to select one to put in production but we can't decide how do we do this ?
One way to do this to train both of them and then see which one is generalising well on test data.
Once we have the best of both we need to select the right hyper parameters so this could be done by training around 100 models with 100 different hyper-parameters now this is giving a error of only 5% but when we put this in production it is giving an error of 15%.
So what happened ? We trained the model too many times in the test data that the model and hyper-parameters are now optimised for the test set as well.
To solve this we need to again holdout a set of data from the test set called validation set to evaluate several candidate models and select the best one.
- We train the model on training set - validation set
- Find which one of those model performs best on the full training set.
- Evaluate final model on the test set to get estimate of the generalisation error.
Data Mismatch
There might become cases where we have a lot of data but the data is not representative enough. If we want to build a flower species classifier app we could download millions of flower images from the internet and then train the model but the data here is not representative of the photo taken by the app on a mobile phone. We might have a very small set of data that is taken in the phone we need to distribute this in the training and validation set so that we could figure out if the model is generalising well and would work in our production environment. To find if our model is not generalising but instead is overfitting we can hold out a part of the training set (images from the internet, not mobile app) called train-dev set and train the model on the training set and test it on the train-dev set if it is performing well the model is not overfitting and yet it performs badly one validation set there is data-mismatch we need to figure out how to preprocess the data from the internet to look like mobile app images.
Sources
Github Repo of handson-ml2 : https://github.com/ageron/handson-ml2
Website to purchase the book : https://www.oreilly.com/library/view/hands-on-machine-learning/9781492032632/
My GitHub repo on Chapter 1 : https://github.com/abhijitramesh/learning-handson-ml2/blob/main/Chapter 1 Types of Machine Learning Systems.ipynb
Subscribe to the newsletter
Get emails from me about machine learning, tech, statups and more.
- subscribers